


Minecraft robot golem mod
19 comments
How a massive bet on bitcoin paid off for peter thiels founders fundkopitiam bot
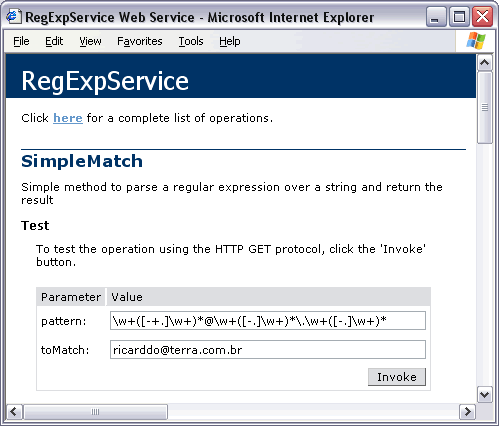
The regular expression I receive the most feedback, not to mention "bug" reports on, is the one you'll find right on this site's home page: This regular expression, I claim, matches any email address. Most of the feedback I get refutes that claim by showing one email address that this regex doesn't match. Usually, the "bug" report also includes a suggestion to make the regex "perfect".
As I explain below, my claim only holds true when one accepts my definition of what a valid email address really is, and what it's not. If you want to use a different definition, you'll have to adapt the regex. Matching a valid email address is a perfect example showing that 1 before writing a regex, you have to know exactly what you're trying to match, and what not; and 2 there's often a trade-off between what's exact, and what's practical.
If you're looking for a quick solution, you only need to read the next paragraph. If you want to know all the trade-offs and get plenty of alternatives to choose from, read on. If you want to use the regular expression above, there's two things you need to understand. First, long regexes make it difficult to nicely format paragraphs.
So I didn't include a-z in any of the three character classes. This regex is intended to be used with your regex engine's "case insensitive" option turned on. You'd be surprised how many "bug" reports I get about that.
Second, the above regex is delimited with word boundaries , which makes it suitable for extracting email addresses from files or larger blocks of text. If you want to check whether the user typed in a valid email address, replace the word boundaries with start-of-string and end-of-string anchors , like this: The previous paragraph also applies to all following examples. And you have to turn on the case insensitive matching option. Before ICANN made it possible for any well-funded company to create their own top-level domains, the longest top-level domains were the rarely used.
The most common top-level domains were 2 letters long for country-specific domains, and 3 or 4 letters long for general-purpose domains like. A lot of regexes for validating email addresses you'll find in various regex tutorials and references still assume the top-level domain to be fairly short. There's only one little difference between this regex and the one at the top of this page. The 4 at the end of the regex restricts the top-level domain to 4 characters. If you use this regex with anchors to validate the email address entered on your order form, fabio disapproved.
Each part of a domain name can be no longer than 63 characters. There are no single-digit top-level domains and none contain digits. Email addresses can be on servers on a subdomain as in john server. All of the above regexes match this email address, because I included a dot in the character class after the symbol.
But the above regexes also match john aol You can exclude such matches by replacing [ A - Z 0 - 9. I removed the dot from the character class and instead repeated the character class and the following literal dot. If you want to avoid your system choking on arbitrarily large input, you can replace the infinite quantifiers with finite ones. There's no direct limit on the number of subdomains.
But the maximum length of an email address that can be handled by SMTP is characters. So with a single-character local part, a two-letter top-level domain and single-character sub-domains, is the maximum number of sub-domains. The previous regex does not actually limit email addresses to characters. If each part is at its maximum length, the regex can match strings up to characters in length.
You can reduce that by lowering the number of allowed sub-domains from to something more realistic like 8. I've never seen an email address with more than 4 subdomains.
If you want to enforce the character limit, the best solution is to check the length of the input string before you even use a regex. Though this requires a few lines of procedural code, checking the length of a string is near-instantaneous.
If you need to do everything with one regex, you'll need a regex flavor that supports lookahead. When the lookahead succeeds, the remainder of the regex makes a second pass over the string to check for proper placement of the sign and the dots.
All of these regexes allow the characters. When using lookahead to check the overall length of the address, the first character can be checked in the lookahead.
We don't need to repeat the initial character check when checking the length of the local part. This regex is too long to fit the width of the page, so let's turn on free-spacing mode:. But they cannot begin or end with a hyphen. The non-capturing group makes the middle of the domain and the final letter or digit optional as a whole to ensure that we allow single-character domains while at the same time ensuring that domains with two or more characters do not end with a hyphen.
The overall regex starts to get quite complicated:. This is the most efficient way. This regex does not do any backtracking to match a valid domain name. It matches all letters and digits at the start of the domain name. If there are no hyphens, the optional group that follows fails immediately. If there are hyphens, the group matches each hyphen followed by all letters and digits up to the next hyphen or the end of the domain name. We can't enforce the maximum length when hyphens must be paired with a letter or digit, but letters and digits can stand on their own.
But we can use the lookahead technique that we used to enforce the overall length of the email address to enforce the length of the domain name while disallowing consecutive hyphens: Notice that the lookahead also checks for the dot that must appear after the domain name when it is fully qualified in an email address.
Without checking for the dot, the lookahead would accept longer domain names. Since the lookahead does not consume the text it matches, the dot is not included in the overall match of this regex.
When we put this regex into the overall regex for email addresses, the dot will be matched as it was in the previous regexes:.
If we include the lookahead to check the overall length, our regex makes two passes over the local part, and three passes over the domain names to validate everything:.
On a modern PC or server this regex will perform just fine when validating a single character email address. Rejecting longer input would even be faster because the regex will fail when the lookahead fails during first pass. But I wouldn't recommend using a regex as complex as this to search for email addresses through a large archive of documents or correspondence.
You're better off using the simple regex at the top of this page to quickly gather everything that looks like an email address. Deduplicate the results and then use a stricter regex if you want to further filter out invalid addresses. And speaking of backtracking, none of the regexes on this page do any backtracking to match valid email addresses.
But particularly the latter ones may do a fair bit of backtracking on something that's not quite a valid email address. If your regex flavor supports possessive quantifiers, you can eliminate all backtracking by making all quantifiers possessive. Because no backtracking is needed to find matches, doing this does not change what is matched by these regexes.
It only allows them to fail faster when the input is not a valid email address. We can do the same with our most complex regex:. An important trade-off in all these regexes is that they only allow English letters, digits, and the most commonly used special symbols. The main reason is that I don't trust all my email software to be able to handle much else.
Blindly inserting this email address into an SQL query, for example, will at best cause it to fail when strings are delimited with single quotes and at worst open your site up to SQL injection attacks. And of course, it's been many years already that domain names can include non-English characters.
But most software still sticks to the 37 characters Western programmers are used to. Supporting internationalized domains opens up a whole can of worms of how the non-ASCII characters should be encoded. But perhaps it is telling that http: The conclusion is that to decide which regular expression to use, whether you're trying to match an email address or something else that's vaguely defined, you need to start with considering all the trade-offs.
How bad is it to match something that's not valid? How bad is it not to match something that is valid? How complex can your regular expression be? How expensive would it be if you had to change the regular expression later because it turned out to be too broad or too narrow?
Different answers to these questions will require a different regular expression as the solution. My email regex does what I want, but it may not do what you want. Don't go overboard in trying to eliminate invalid email addresses with your regular expression. The reason is that you don't really know whether an address is valid until you try to send an email to it. And even that might not be enough. Even if the email arrives in a mailbox, that doesn't mean somebody still reads that mailbox.
If you really need to be sure an email address is valid, you'll need to send an email to it that contains a code or link for the recipient to perform a second authentication step. And if you're doing that, then there is little point in using a regex that may reject valid email addresses. The same principle applies in many situations. When trying to match a valid date , it's often easier to use a bit of arithmetic to check for leap years, rather than trying to do it in a regex.
Use a regular expression to find potential matches or check if the input uses the proper syntax, and do the actual validation on the potential matches returned by the regular expression. Regular expressions are a powerful tool, but they're far from a panacea. Maybe you're wondering why there's no "official" fool-proof regex to match email addresses.
Well, there is an official definition, but it's hardly fool-proof.